Wie installiert und konfiguriert man Apache Hadoop unter Ubuntu 20.04
Apache Hadoop ist ein Open-Source-Framework zur Verwaltung, Speicherung und Verarbeitung von Daten für verschiedene große Datenanwendungen, die unter geclusterten Systemen laufen. Es ist in Java mit etwas nativem Code in C und Shell-Skripten geschrieben. Es verwendet ein verteiltes Dateisystem (HDFS) und skaliert von einzelnen Servern bis zu Tausenden von Maschinen.
Apache Hadoop basiert auf den vier Hauptkomponenten:
- Hadoop Common : Es ist die Sammlung von Dienstprogrammen und Bibliotheken, die von anderen Hadoop-Modulen benötigt werden.
- HDFS : Auch bekannt als Hadoop Distributed File System, das über mehrere Knoten verteilt ist.
- MapReduce : Dies ist ein Framework, das zum Schreiben von Anwendungen zur Verarbeitung großer Datenmengen verwendet wird.
- Hadoop YARN : Auch bekannt als Yet Another Resource Negotiator ist die Ressourcenverwaltungsschicht von Hadoop.
In diesem Tutorial erläutern wir, wie ein Hadoop-Cluster mit nur einem Knoten unter Ubuntu 20.04 eingerichtet wird.
Voraussetzungen
- Ein Server mit Ubuntu 20.04 mit 4 GB RAM.
- Auf Ihrem Server ist ein Root-Passwort konfiguriert.
Aktualisieren der Systempakete
Bevor Sie beginnen, ist es empfehlenswert, Ihre Systempakete auf die neueste Version zu aktualisieren. Sie können dies mit folgendem Befehl tun:
apt-get update -y apt-get upgrade -y
Sobald Ihr System aktualisiert ist, starten Sie es neu, um die Änderungen zu implementieren.
Java installieren
Apache Hadoop ist eine Java-basierte Anwendung. Sie müssen also Java auf Ihrem System installieren. Sie können es mit dem folgenden Befehl installieren:
apt-get install default-jdk default-jre -y
Nach der Installation können Sie die installierte Version von Java mit dem folgenden Befehl überprüfen:
java -version
Sie sollten die folgende Ausgabe erhalten:
openjdk version "11.0.7" 2020-04-14 OpenJDK Runtime Environment (build 11.0.7+10-post-Ubuntu-3ubuntu1) OpenJDK 64-Bit Server VM (build 11.0.7+10-post-Ubuntu-3ubuntu1, mixed mode, sharing)
Hadoop-Benutzer erstellen und kennwortloses SSH einrichten
Zuerst erstellen Sie einen neuen Benutzer namens hadoop mit dem folgenden Befehl:
adduser hadoop
Fügen Sie als nächstes den Benutzer hadoop zur sudo-Gruppe
usermod -aG sudo hadoop
Als nächstes melden Sie sich mit dem hadoop-Benutzer an und erzeugen ein SSH-Schlüsselpaar mit dem folgenden Befehl:
su - hadoop ssh-keygen -t rsa
Sie sollten die folgende Ausgabe erhalten:
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub The key fingerprint is: SHA256:HG2K6x1aCGuJMqRKJb+GKIDRdKCd8LXnGsB7WSxApno hadoop@ubuntu2004 The key's randomart image is: +---[RSA 3072]----+ |..=.. | | O.+.o . | |oo*.o + . o | |o .o * o + | |o+E.= o S | |=.+o * o | |*.o.= o o | |=+ o.. + . | |o .. o . | +----[SHA256]-----+
Fügen Sie als nächstes diesen Schlüssel zu den autorisierten ssh-Schlüsseln hinzu und erteilen Sie die entsprechende Erlaubnis:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
Als nächstes verifizieren Sie die kennwortlose SSH-Version mit folgendem Befehl:
ssh localhost
Sobald Sie sich ohne Passwort angemeldet haben, können Sie mit dem nächsten Schritt fortfahren.
Hadoop installieren
Melden Sie sich zuerst mit dem hadoop-Benutzer an und laden Sie die neueste Version von Hadoop mit dem folgenden Befehl herunter:
su - hadoop wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
Sobald der Download abgeschlossen ist, extrahieren Sie die heruntergeladene Datei mit dem folgenden Befehl:
tar -xvzf hadoop-3.2.1.tar.gz
Als nächstes verschieben Sie das extrahierte Verzeichnis nach /usr/local/:
sudo mv hadoop-3.2.1 /usr/local/hadoop
Erstellen Sie als Nächstes ein Verzeichnis zum Speichern des Protokolls mit dem folgenden Befehl:
sudo mkdir /usr/local/hadoop/logs
Ändern Sie als nächstes den Eigentümer des hadoop-Verzeichnisses in hadoop:
sudo chown -R hadoop:hadoop /usr/local/hadoop
Als nächstes müssen Sie die Hadoop-Umgebungsvariablen konfigurieren. Sie können dies tun, indem Sie die Datei ~/.bashrc editieren:
nano ~/.bashrc
Fügen Sie die folgenden Zeilen hinzu:
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Speichern und schließen Sie die Datei, wenn Sie fertig sind. Aktivieren Sie dann die Umgebungsvariablen mit dem folgenden Befehl:
source ~/.bashrc
Konfigurieren von Hadoop
In diesem Abschnitt erfahren wir, wie Sie Hadoop auf einem einzelnen Knoten einrichten.
Java-Umgebungsvariablen konfigurieren
Als nächstes müssen Sie Java-Umgebungsvariablen in hadoop-env.sh definieren, um YARN, HDFS, MapReduce und Hadoop-bezogene Projekteinstellungen zu konfigurieren.
Suchen Sie zunächst den korrekten Java-Pfad mit dem folgenden Befehl:
which javac
Sie sollten die folgende Ausgabe sehen:
/usr/bin/javac
Als nächstes suchen Sie das Verzeichnis OpenJDK mit folgendem Befehl:
readlink -f /usr/bin/javac
Sie sollten die folgende Ausgabe sehen:
/usr/lib/jvm/java-11-openjdk-amd64/bin/javac
Als nächstes editieren Sie die Datei hadoop-env.sh und definieren den Java-Pfad:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Fügen Sie die folgenden Zeilen hinzu:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
Als nächstes müssen Sie auch die Javax-Aktivierungsdatei herunterladen. Sie können sie mit dem folgenden Befehl herunterladen:
cd /usr/local/hadoop/lib sudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jar
Sie können nun die Hadoop Version mit dem folgenden Befehl überprüfen:
hadoop version
Sie sollten die folgende Ausgabe erhalten: Speichern und schließen Sie die Datei:
Hadoop 3.2.1 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842 Compiled by rohithsharmaks on 2019-09-10T15:56Z Compiled with protoc 2.5.0 From source with checksum 776eaf9eee9c0ffc370bcbc1888737 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.2.1.jar
Konfigurieren Sie die Datei core-site.xml
Als nächstes müssen Sie die URL für Ihren NameNode angeben. Sie können dies tun, indem Sie die Datei core-site.xml bearbeiten:
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml
Fügen Sie die folgenden Zeilen hinzu:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
<description>The default file system URI</description>
</property>
</configuration>
Speichern und schließen Sie die Datei, wenn Sie fertig sind:
Konfigurieren Sie die Datei hdfs-site.xml
Als Nächstes müssen Sie den Speicherort für die Knoten-Metadaten, die fsimage-Datei und die Bearbeitungsprotokolldatei definieren. Sie können dies tun, indem Sie die Datei hdfs-site.xml bearbeiten. Erstellen Sie zunächst ein Verzeichnis zum Speichern der Knotenmetadaten:
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfs
Bearbeiten Sie als nächstes die Datei hdfs-site.xml und definieren Sie den Speicherort des Verzeichnisses:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Fügen Sie die folgenden Zeilen hinzu:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
Speichern und schließen Sie die Datei.
Konfigurieren der Datei mapred-site.xml
Als nächstes müssen Sie MapReduce Werte definieren. Sie können sie definieren, indem Sie die Datei mapred-site.xml bearbeiten:
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Fügen Sie die folgenden Zeilen hinzu:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Speichern Sie die Datei und schließen Sie sie.
Konfigurieren Sie die Datei yarn-site.xml
Als nÃ?chstes mÃ?ssen Sie die Datei yarn-site.xml bearbeiten und YARN-bezogene Einstellungen definieren:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Fügen Sie die folgenden Zeilen hinzu:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Speichern und schließen Sie die Datei, wenn Sie fertig sind.
HDFS-Namensknoten formatieren
Als nächstes müssen Sie die Hadoop-Konfiguration validieren und den HDFS NameNode formatieren.
Melden Sie sich zuerst mit dem Hadoop Benutzer an und formatieren Sie den HDFS NameNode mit dem folgenden Befehl:
su - hadoop hdfs namenode -format
Sie sollten die folgende Ausgabe erhalten:
2020-06-07 11:35:57,691 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,692 INFO util.GSet: 0.25% max memory 1.9 GB = 5.0 MB 2020-06-07 11:35:57,692 INFO util.GSet: capacity = 2^19 = 524288 entries 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 2020-06-07 11:35:57,712 INFO util.GSet: Computing capacity for map NameNodeRetryCache 2020-06-07 11:35:57,712 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,712 INFO util.GSet: 0.029999999329447746% max memory 1.9 GB = 611.9 KB 2020-06-07 11:35:57,712 INFO util.GSet: capacity = 2^16 = 65536 entries 2020-06-07 11:35:57,743 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1242120599-69.87.216.36-1591529757733 2020-06-07 11:35:57,763 INFO common.Storage: Storage directory /home/hadoop/hdfs/namenode has been successfully formatted. 2020-06-07 11:35:57,817 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 2020-06-07 11:35:57,972 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 398 bytes saved in 0 seconds . 2020-06-07 11:35:57,987 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-06-07 11:35:58,000 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-06-07 11:35:58,003 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at ubuntu2004/69.87.216.36 ************************************************************/
Starten Sie den Hadoop-Cluster
Starten Sie zunächst den NameNode und DataNode mit dem folgenden Befehl:
start-dfs.sh
Sie sollten die folgende Ausgabe erhalten:
Starting namenodes on [0.0.0.0] Starting datanodes Starting secondary namenodes [ubuntu2004]
Starten Sie als nächstes den YARN-Ressourcen- und Knoten-Manager mit folgendem Befehl: Starten Sie den YARN-Ressourcen- und Knoten-Manager mit folgendem Befehl
start-yarn.sh
Sie sollten die folgende Ausgabe erhalten:
Starting resourcemanager Starting nodemanagers
Sie können sie nun mit dem folgenden Befehl verifizieren:
jps
Sie sollten die folgende Ausgabe erhalten:
5047 NameNode 5850 Jps 5326 SecondaryNameNode 5151 DataNode
Zugang zum Hadoop Web Interface
Sie können jetzt auf den Hadoop NameNode über die URL http://your-server-ip:9870 zugreifen. Sie sollten den folgenden Bildschirm sehen:
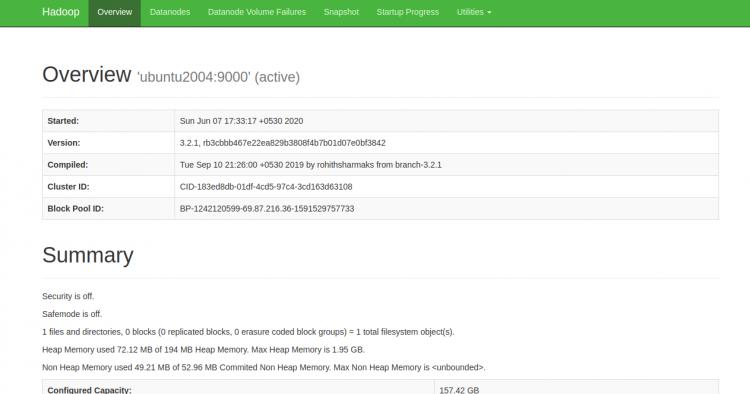
Sie können auf die einzelnen DataNodes auch über die URL http://your-server-ip:9864 zugreifen. Sie sollten den folgenden Bildschirm sehen:
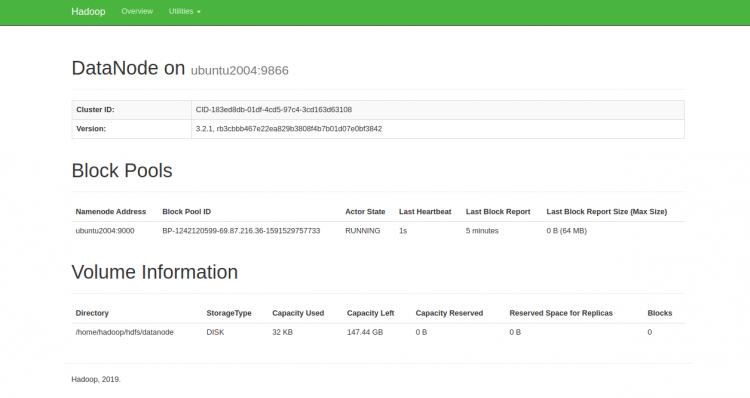
Um auf den YARN Resource Manager zuzugreifen, verwenden Sie die URL http://your-server-ip:8088. Sie sollten den folgenden Bildschirm sehen:
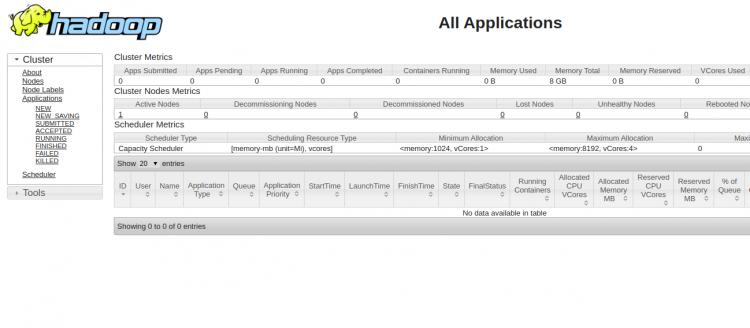
Schlussfolgerung
Herzlichen Glückwunsch! Sie haben Hadoop erfolgreich auf einem einzelnen Knoten installiert. Sie können nun damit beginnen, grundlegende HDFS-Befehle zu untersuchen und einen vollständig verteilten Hadoop-Cluster zu entwerfen. Zögern Sie nicht, mich zu fragen, wenn Sie Fragen haben.