Wie man Apache Spark unter Ubuntu 20.04 installiert
Apache Spark ist ein Open-Source-Framework und ein universell einsetzbares Cluster-Computersystem. Spark bietet High-Level-APIs in Java, Scala, Python und R, die allgemeine Ausführungsgraphen unterstützen. Es wird mit integrierten Modulen für Streaming, SQL, maschinelles Lernen und Diagrammverarbeitung geliefert. Es ist in der Lage, eine große Datenmenge zu analysieren und diese über den Cluster zu verteilen und die Daten parallel zu verarbeiten.
In diesem Tutorial wird erklärt, wie der Cluster-Computing-Stack Apache Spark unter Ubuntu 20.04 installiert wird.
Voraussetzungen
- Ein Server, auf dem ein Ubuntu 20.04-Server läuft.
- Der Server ist mit einem Root-Passwort konfiguriert.
Erste Schritte
Zuerst müssen Sie Ihre Systempakete auf die neueste Version aktualisieren. Sie können sie alle mit dem folgenden Befehl aktualisieren:
apt-get update -y
Sobald alle Pakete aktualisiert sind, können Sie mit dem nächsten Schritt fortfahren.
Java installieren
Apache Spark ist eine Java-basierte Anwendung. Daher muss Java in Ihrem System installiert sein. Sie können es mit dem folgenden Befehl installieren:
apt-get install default-jdk -y
Sobald Java installiert ist, überprüfen Sie die installierte Version von Java mit dem folgenden Befehl:
java --version
Sie sollten die folgende Ausgabe sehen:
openjdk 11.0.8 2020-07-14 OpenJDK Runtime Environment (build 11.0.8+10-post-Ubuntu-0ubuntu120.04) OpenJDK 64-Bit Server VM (build 11.0.8+10-post-Ubuntu-0ubuntu120.04, mixed mode, sharing)
Scala installieren
Apache Spark wird unter Verwendung der Scala entwickelt. Sie müssen also Scala in Ihrem System installieren. Sie können es mit dem folgenden Befehl installieren:
apt-get install scala -y
Nach der Installation von Scala. Sie können die Scala-Version mit folgendem Befehl verifizieren: Nach der Installation von Scala:
scala -version
Sie sollten die folgende Ausgabe sehen:
Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
Nun verbinden Sie sich mit der Scala-Schnittstelle mit folgendem Befehl:
scala
Sie sollten die folgende Ausgabe sehen: Sie sollten die folgende Ausgabe sehen:
Welcome to Scala 2.11.12 (OpenJDK 64-Bit Server VM, Java 11.0.8). Type in expressions for evaluation. Or try :help.
Testen Sie nun Scala mit folgendem Befehl: Testen Sie Scala mit folgendem Befehl:
scala> println("Hitesh Jethva")
Sie sollten die folgende Ausgabe erhalten: Sie sollten die folgende Ausgabe erhalten:
Hitesh Jethva
Apache Spark installieren
Zunächst müssen Sie die neueste Version von Apache Spark von der offiziellen Website herunterladen. Zum Zeitpunkt der Erstellung dieses Tutorials ist die neueste Version von Apache Spark 2.4.6. Sie können sie mit dem folgenden Befehl in das Verzeichnis /opt herunterladen:
cd /opt wget https://archive.apache.org/dist/spark/spark-2.4.6/spark-2.4.6-bin-hadoop2.7.tgz
Entpacken Sie die heruntergeladene Datei nach dem Herunterladen mit dem folgenden Befehl:
tar -xvzf spark-2.4.6-bin-hadoop2.7.tgz
Benennen Sie dann das extrahierte Verzeichnis in Spark um, wie unten gezeigt:
mv spark-2.4.6-bin-hadoop2.7 spark
Als nächstes müssen Sie die Spark-Umgebung so konfigurieren, dass Sie Spark-Befehle problemlos ausführen können. Sie können sie durch Bearbeiten der .bashrc-Datei konfigurieren:
nano ~/.bashrc
Fügen Sie die folgenden Zeilen am Ende der Datei hinzu:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Speichern und schließen Sie die Datei und aktivieren Sie dann die Umgebung mit dem folgenden Befehl:
source ~/.bashrc
Starten Sie Spark Master Server
An diesem Punkt wird Apache Spark installiert und konfiguriert. Starten Sie nun den Spark-Masterserver mit dem folgenden Befehl:
start-master.sh
Sie sollten die folgende Ausgabe sehen:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-ubuntu2004.out
Standardmäßig lauscht Spark auf Port 8080. Sie können dies mit dem folgenden Befehl überprüfen:
ss -tpln | grep 8080
Sie sollten die folgende Ausgabe sehen:
LISTEN 0 1 *:8080 *:* users:(("java",pid=4930,fd=249))
Öffnen Sie nun Ihren Webbrowser und greifen Sie über die URL http://your-server-ip:8080 auf die Webschnittstelle von Spark zu. Sie sollten den folgenden Bildschirm sehen:
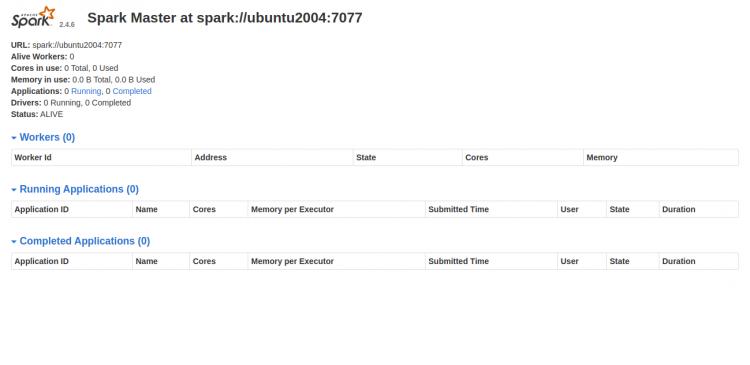
Spark-Worker-Prozess starten
Wie Sie sehen können, läuft der Master-Dienst von Spark unter spark://your-server-ip:7077. Sie können also diese Adresse verwenden, um den Spark-Worker-Prozess mit dem folgenden Befehl zu starten:
start-slave.sh spark://your-server-ip:7077
Sie sollten die folgende Ausgabe sehen:
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-ubuntu2004.out
Gehen Sie nun zum Spark-Dashboard und aktualisieren Sie den Bildschirm. Sie sollten den Spark-Worker-Prozess auf dem folgenden Bildschirm sehen:
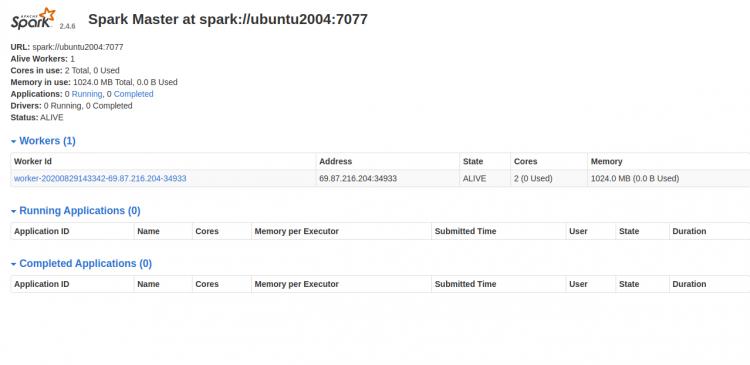
Arbeiten mit Spark Shell
Sie können den Spark-Server auch über die Befehlszeile verbinden. Sie können ihn mit dem Befehl spark-shell wie unten dargestellt verbinden:
spark-shell
Sobald die Verbindung hergestellt ist, sollten Sie die folgende Ausgabe sehen:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.11-2.4.6.jar) to method java.nio.Bits.unaligned()
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
20/08/29 14:35:07 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://ubuntu2004:4040
Spark context available as 'sc' (master = local[*], app id = local-1598711719335).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 11.0.8)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Wenn Sie Python in Spark verwenden möchten. Sie können das Befehlszeilen-Dienstprogramm pyspark verwenden.
Installieren Sie zunächst die Python-Version 2 mit dem folgenden Befehl:
apt-get install python -y
Nach der Installation können Sie Spark mit dem folgenden Befehl verbinden:
pyspark
Sobald die Verbindung hergestellt ist, sollten Sie die folgende Ausgabe erhalten:
Python 2.7.18rc1 (default, Apr 7 2020, 12:05:55)
[GCC 9.3.0] on linux2
Type "help", "copyright", "credits" or "license" for more information.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.11-2.4.6.jar) to method java.nio.Bits.unaligned()
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
20/08/29 14:36:40 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Python version 2.7.18rc1 (default, Apr 7 2020 12:05:55)
SparkSession available as 'spark'.
>>>
Wenn Sie den Master- und Slave-Server stoppen wollen. Sie können dies mit dem folgenden Befehl tun:
stop-slave.sh stop-master.sh
Schlussfolgerung
Herzlichen Glückwunsch! Sie haben Apache Spark erfolgreich auf dem Ubuntu 20.04 Server installiert. Nun sollten Sie in der Lage sein, grundlegende Tests durchzuführen, bevor Sie mit der Konfiguration eines Spark-Clusters beginnen. Zögern Sie nicht, mich zu fragen, wenn Sie Fragen haben.