Erstellen einer AWS RDS-Replik für MySql
Amazon RDS ist ein einfach einzurichtender, von AWS verwalteter Datenbankdienst. Amazon RDS unterstützt zwei Arten von Replikationsfunktionen: 1) Multi-AZ-Einsätze 2) Read Replicas.
Bei der Multi-AZ-Bereitstellung speichert RDS eine Standby-Datenbankreplik in einer anderen Availability Zone. Hier werden Datenbankaktualisierungen gleichzeitig auf den Hauptknoten und den Replikationsknoten angewendet. Bei einem Failover verlagert RDS die Operationen automatisch auf den Standby-Replikationsknoten, ohne dass es zu Unterbrechungen der Datenbankoperationen kommt.
Im Falle einer Read Replica gibt es auch eine Standby Replica, auf die jedoch vor einem Failover nicht direkt zugegriffen werden kann. Dieses Verhalten kann für die elastische Skalierung einer DB-Instanz genutzt werden. Für leseintensive Datenbankarbeitslasten können mehrere Replikate einer Quelldatenbankinstanz in derselben AWS-Region oder in einer anderen AWS-Region erstellt werden.
Seit dem 11. Januar 2018 können Amazon RDS-Lesereplikate für MySQL- und MariaDB-Datenbanken nun auch in mehreren Verfügbarkeitszonen bereitgestellt werden.
Die Updates der primären oder Master-Datenbank werden asynchron an die Read Replicas übertragen. Neben der Skalierbarkeit können Read Replicas auch für die Disaster Recovery genutzt werden. Wenn z.B. die primäre DB-Instanz ausfällt, kann die Replik als eigenständige Instanz gestartet werden und im Namen der primären Datenbank arbeiten.
Was werden wir behandeln?
In dieser Anleitung wird gezeigt, wie man eine Read Replica einer MySql RDS-Datenbankinstanz erstellt.
Wichtige Hinweise zum Thema Read Replica
Bevor wir fortfahren, solltest du einige wichtige Hinweise zu Read Replicas beachten:
- Es empfiehlt sich, eine Read Replica auf die gleiche Weise zu konfigurieren wie eine Master-DB-Instanz.
- Die einzigen unterstützten Datenbank-Engines für Read Replicas sind: MariaDB, Microsoft SQL Server, MySQL, Oracle und PostgreSQL.
- Der Standard-Speichertyp einer Read Replica ist derselbe wie der der Quell-DB-Instanz. Der Speichertyp kann auch bei der Erstellung der Read Replica geändert werden.
- Bitte beachte, dass du die Speichergröße, die einer Read Replica zugewiesen ist, nicht um weniger als 10 Prozent erhöhen kannst, wenn du sie änderst.
- Die zirkuläre Replikation wird von Amazon RDS nicht unterstützt.
- Replikate verschiedener DB-Engines weisen einige Unterschiede auf.
- Bei der Erstellung einer Read Replica kommt es zu einer kurzen E/A-Unterbrechung.
- Um eine Read Replica zu erstellen, sollten automatische Backups auf der Quell-DB-Instanz aktiviert werden. Dazu musst du den Wert für die Aufbewahrungszeit der Sicherungen auf einen Wert größer als „0“ setzen.
Erstellen von Read Replicas über die AWS Management Console
Bevor wir mit der Read Replica fortfahren, musst du deine DB-Instance starten und zum Laufen bringen. Rufe die RDS-Verwaltungskonsole auf. Hier sehen wir, dass unsere DB-Instanz „database-1“, die auf der MySQL-DB basiert, läuft:

Hinweis: Um eine Read Replica zu erstellen, können wir die AWS Konsole, die AWS CLI und die RDS API verwenden.
Unsere primäre Datenbankkonfiguration sieht wie folgt aus:
DB instance identifier: ‘database-1’
Database engine: MySql
Database version: 8.0.28
Master username: ‘Your-username’
Master password: ‘Your-password’
DB instance class: db.t2.micro (Free-tier)
Storage size: 20 GiB
Public Access: ‘No’
Automated backups: ‘Enabled’
Mit der obigen DB-Konfiguration fahren wir nun mit der Read Replica fort:
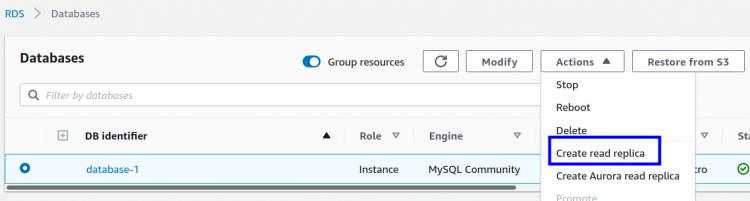
Schritt 1. Wähle in der RDS-Verwaltungskonsole die Ziel-DB-Instanz aus. Klicke nun auf das Dropdown-Menü „Aktion“ und wähle die Option „Lese-Replikat erstellen“:
Schritt 2. Auf der nächsten Seite sind einige Einstellungen bereits nach dem Best-Practice-Ansatz vorausgewählt. Wir halten uns hier an die Best Practice, können sie aber auch ändern.
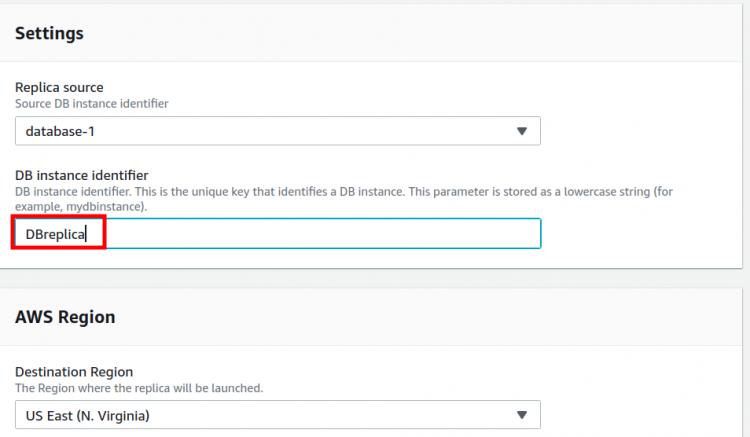
Schritt 3. Wähle unter „Replikationsquelle“ die Quell-DB-Instanz für die Read Replica aus. Gib einen Namen für die DB-Instanz der Read Replica ein („DBreplica“ in unserem Fall). Wähle außerdem eine Region für den Start der Read Replica. Wir haben für die Read Replica dieselbe Region ausgewählt wie für die DB-Instanz.
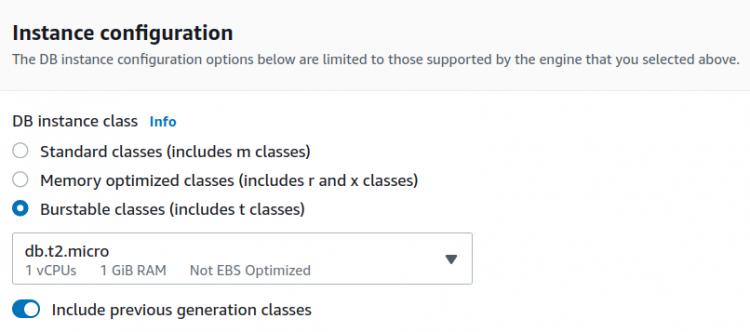
Wir bleiben bei den voreingestellten Einstellungen für die DB-Instanzklasse und die Speicherdetails.
Die Option zur automatischen Skalierung des Speichers ist im Abschnitt Speicher bereits aktiviert.
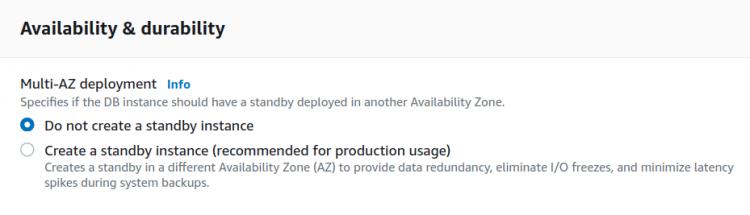
Schritt 4. Unter Multi-AZ-Bereitstellung kannst du Fallback-Support oder Standby für die Replik erstellen, indem du „Ja“ auswählst. Für den Moment überspringen wir diese Option:
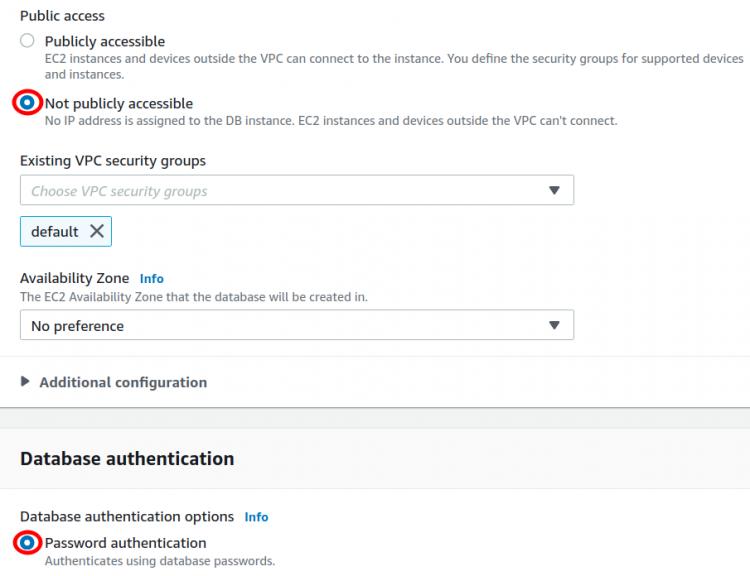
Schritt 5. Unser Lese-Replikat ist nicht öffentlich zugänglich, da wir die Option „Nicht öffentlich zugänglich“ gewählt haben. Außerdem basiert die Datenbankauthentifizierung auf der „Passwortauthentifizierung“.
Schritt 6. Da wir die Verschlüsselungsoption für die Quell-DB-Instanz nicht aktiviert haben, lassen wir sie auch hier aus. Auch die Überwachung, die Protokollierungsoption und der Löschschutz bleiben unangetastet.
Schritt 7. In der zusätzlichen Konfigurationsoption der Datenbank kann der Portwert auf einen anderen als den Standardwert geändert werden. Um die Tags in Snapshots zu kopieren, aktiviere das Kontrollkästchen „Tags in Snapshots kopieren“. Die IAM DB-Authentifizierung kann für die Verwaltung der Datenbank über einen IAM-Benutzer aktiviert werden. Eine weitere Option ist die Aktivierung von kleineren Datenbank-Updates.
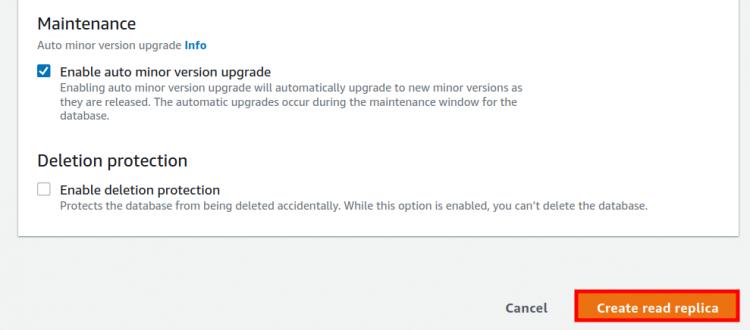
Schritt 8. Klicke nun auf die Schaltfläche „Read Replica erstellen“, um die Erstellung des Replikats zu starten.
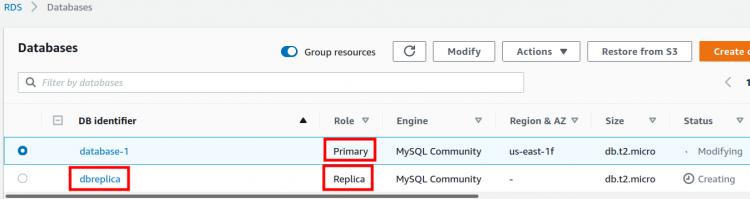
Wenn du lieber die AWS CLI-Methode verwendest, kannst du die Read Replica mit dem Befehl „create-db-instance-read-replica“ und den erforderlichen CLI-Optionen erstellen:
$ aws rds create-db-instance-read-replica --db-instance-identifier DBreplica --source-db-instance-identifier database-1 --max-allocated-storage 1000
Zusammenfassung
In diesem Leitfaden haben wir gesehen, wie man eine Read Replica für eine MySql-Datenbank erstellt. Mit Read Replicas erhältst du eine asynchron kopierte Nur-Lese-Version der primären Datenbank, die dir sowohl Skalierbarkeit als auch eine Standby-Recovery-Datenbank bietet.