So installierst du einen CockroachDB-Cluster unter Debian 11
CockroachDB ist eine verteilte und skalierbare Open-Source-SQL-Datenbank für Cloud-Anwendungen. CockroachDB bietet Konsistenz der nächsten Stufe, eine replizierte SQL-Datenbank und einen transaktionalen Datenspeicher. CockroachDB speichert deine Daten an mehreren Orten und beschleunigt so die Datenbereitstellung. Außerdem ist sie einfach zu skalieren und bietet hohe Verfügbarkeit und Fehlertoleranz für deine Anwendungen.
In diesem Lernprogramm zeigen wir dir, wie du den CockroachDB-Cluster auf einem Debian 11-Server installierst.
Voraussetzungen
- Zwei oder mehr Debian 11 Server.
- Ein Root-Passwort ist auf den Servern konfiguriert.
Installation von CockroachDB auf allen 3 Servern
Für die Installation ist cockroachdb einfach zu installieren. Das liegt daran, dass cockroachdb eine Binärdatei für das Linux-System bereitstellt, die du auf dein System herunterladen kannst.
Lade die cockroachdb-Binärdatei für Linux mit folgendem Befehl herunter. Dieser Befehl lädt die cockroachdb-Binärdatei herunter, entpackt die komprimierte Datei und verschiebt die Binärdatei von cockroachdb in das Verzeichnis /usr/local/bin.
curl https://binaries.cockroachdb.com/cockroach-v21.2.8.linux-amd64.tgz | tar -xz && sudo cp -i cockroach-v21.2.8.linux-amd64/cockroach /usr/local/bin/
Der cockroachdb verwendet die eingebaute GEOS-Bibliothek. Die GEOS-Bibliothek ist in der komprimierten Datei von cockroachdb enthalten und muss im lib-Verzeichnis installiert werden.
Erstelle mit dem unten stehenden Befehl ein neues Verzeichnis /usr/local/lib/cockroach.
mkdir -p /usr/local/lib/cockroach
Kopiere nun die GEOS-Bibliothek in das Verzeichnis /usr/local/lib/cockroach.
cp -i cockroach-v21.2.8.linux-amd64/lib/libgeos.so /usr/local/lib/cockroach/ cp -i cockroach-v21.2.8.linux-amd64/lib/libgeos_c.so /usr/local/lib/cockroach/
Die Grundinstallation von cockroachdb ist auf Debian-Servern installiert.

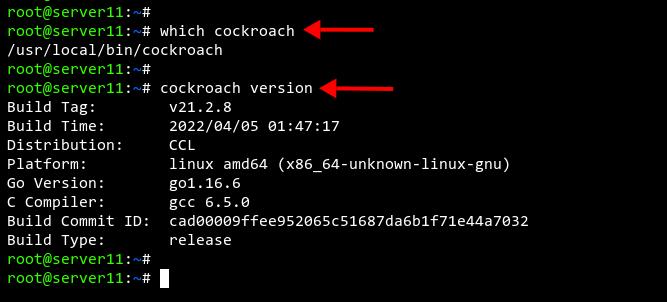
Führe den folgenden Befehl aus, um die cockroachdb-Binärdatei und die aktuelle Version von cockroachdb, die du gerade installiert hast, zu überprüfen.
which cockroach cockroach version
Du erhältst die folgende Ausgabe.
Firewall einrichten
Wenn du die Firewall auf deinen Debian-Servern einsetzt, musst du die Ports von cockroachdb in die Firewall-Konfiguration aufnehmen.
Die cockroachdb verwendet Port 8080 für die webbasierte Verwaltung cockroachdb und Port 26257 für die Benutzerverbindungen und die Cluster-Konfiguration.
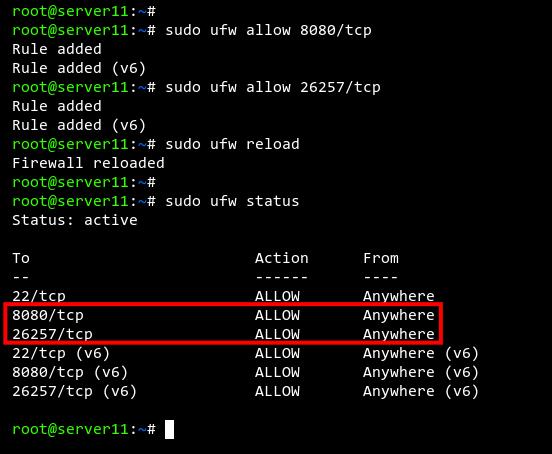
Füge die Ports 8080 und 25267 mit dem folgenden Befehl zur UFW-Firewall hinzu.
sudo ufw allow 8080/tcp sudo ufw allow 26257/tcp
Lade nun die UFW-Firewall-Regeln neu und überprüfe den aktuellen Status der Firewall-Regeln.
sudo ufw reload sudo ufw status
Unten kannst du sehen, dass die Ports 8080 und 25267 zur UFW-Firewall hinzugefügt wurden.
CockroachDB-Cluster initialisieren
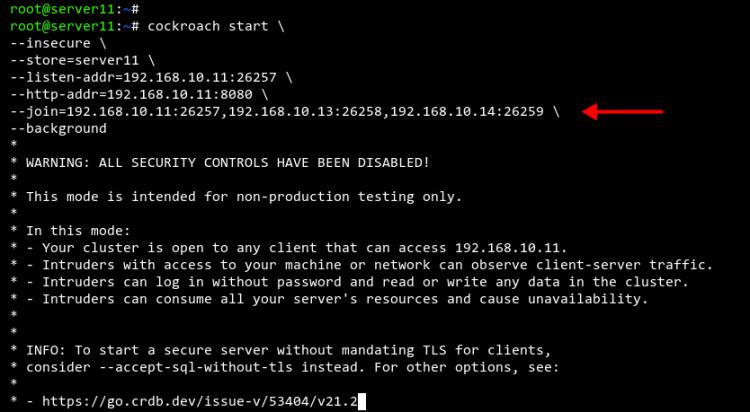
Um den cockroachdb-Cluster zu initialisieren, führe den folgenden Befehl auf dem Server11 aus.
Du musst den Wert der folgenden Optionen ändern:
- –store: zum Speichern der Daten des CockroachDB-Clusters.
- –listen-addr: die IP-Adresse, unter der cockroachdb auf dem Server laufen soll. Der Standardport für cockroachdb ist Port 25267.
- –http-addr: die IP-Adresse, unter der die webbasierte Verwaltung von cockroachdb ausgeführt wird. Die webbasierte Administration von cockroachdb läuft standardmäßig über Port 8080.
cockroach start \ --insecure \ --store=server11 \ --listen-addr=192.168.10.11:26257 \ --http-addr=192.168.10.11:8080 \ --join=192.168.10.11:26257,192.168.10.13:26258,192.168.10.14:26259 \ --background
Du wirst die folgende Ausgabe erhalten.
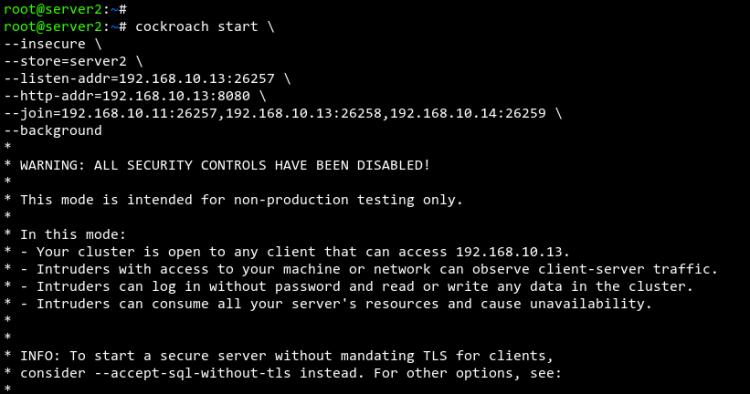
Gehe nun zu Server2 und führe den folgenden Befehl aus, um cockroachdb zu starten und dem Cluster beizutreten. Ändere die IP-Adresse bei –listen-addr und –http-addr auf die IP-Adresse von Server2.
cockroach start \ --insecure \ --store=server2 \ --listen-addr=192.168.10.13:26257 \ --http-addr=192.168.10.13:8080 \ --join=192.168.10.11:26257,192.168.10.13:26258,192.168.10.14:26259 \ --background
Du erhältst die folgende Ausgabe von Server2.
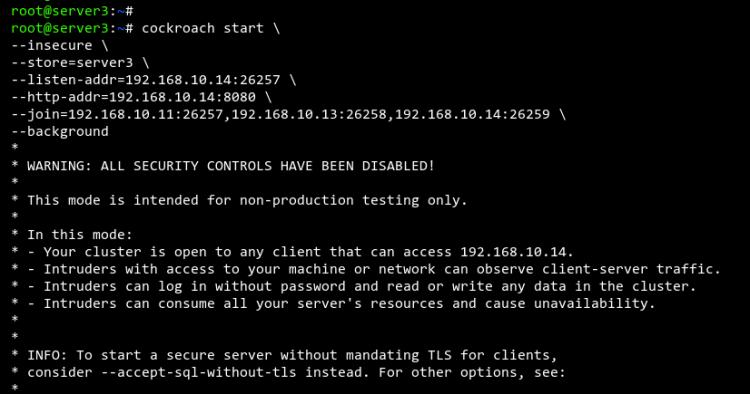
Gehe als nächstes zu Server3 und führe den folgenden Befehl aus, um cockroachdb zu starten und dem cockroachdb-Cluster beizutreten. Ändere außerdem die IP-Adresse von –listen-addr und –http-addr auf die IP-Adresse von Server3.
cockroach start \ --insecure \ --store=server3 \ --listen-addr=192.168.10.14:26257 \ --http-addr=192.168.10.14:8080 \ --join=192.168.10.11:26257,192.168.10.13:26258,192.168.10.14:26259 \ --background
Du wirst die folgende Ausgabe von server3 erhalten.
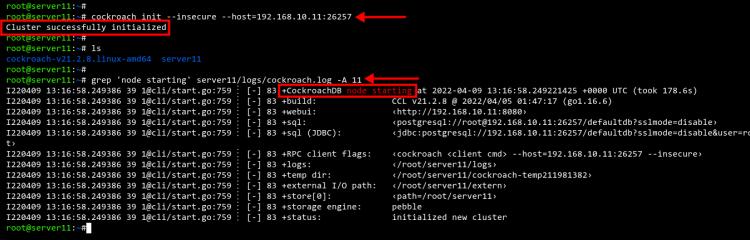
Nachdem alles erledigt ist, gehe zurück zum Server11 und führe den folgenden Befehl aus, um den cockroachdb-Cluster zu initialisieren.
cockroach init --insecure --host=192.168.10.11:26257
Du erhältst die Meldung„cluster successfully initialized„, was bedeutet, dass der cockroachdb cluster erfolgreich initialisiert wurde.
Du kannst den grep-Befehl unten ausführen, um das Protokoll der cockroachdb-Initialisierung zu überprüfen. Tausche das Verzeichnis server11 mit deinem –store cockroachdb Verzeichnis.
grep 'node starting' server11/logs/cockroach.log -A 11
Unten siehst du die Logs der server11 cockroachdb-Cluster-Initialisierung.
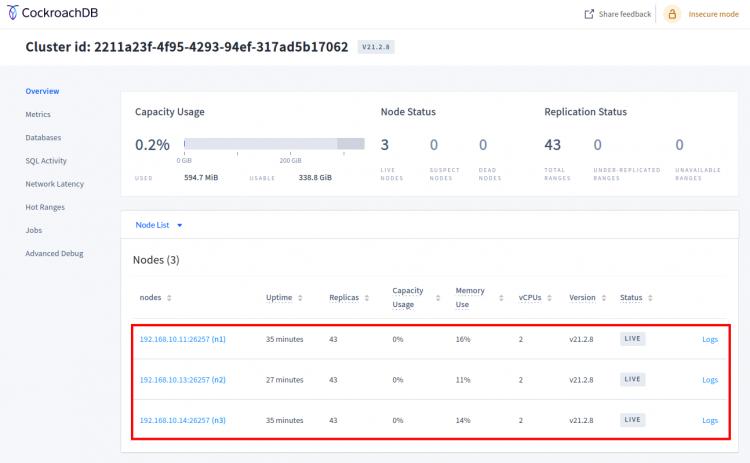
Zuletzt öffnest du deinen Webbrowser und rufst die IP-Adresse des Servers gefolgt von Port 8080 auf.
http://192.168.10.11:8080/
Unten siehst du, dass es drei Knoten auf dem cockroachdb-Cluster gibt.
Testen der Erstellung einer neuen Datenbank auf CockroachDB
Jetzt, wo der cockroachdb-Cluster läuft, kannst du einen beliebigen Server als SQL-Gateway für den Zugriff auf die cockroachdb verwenden.
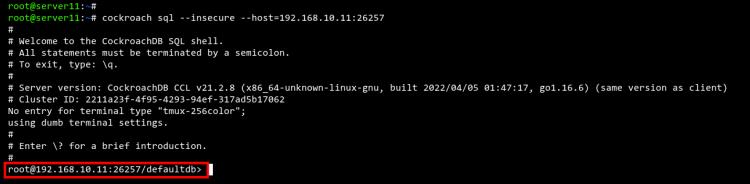
Führe den Befehl cockroach auf dem Server11 aus, um dich mit dem cockroachdb-Cluster zu verbinden.
cockroach sql --insecure --host=192.168.10.11:26257
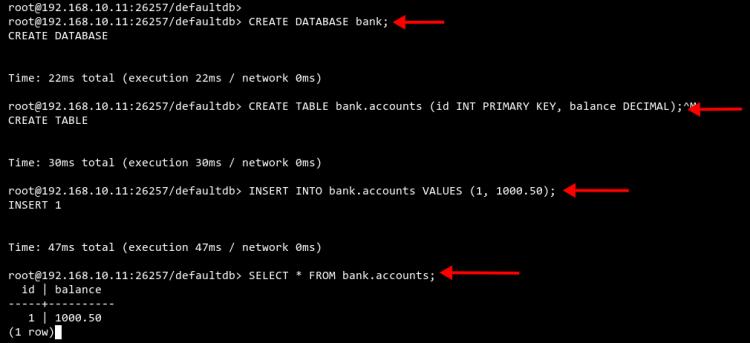
Nachdem du mit der SQL-Shell verbunden bist, führe die folgende Abfrage aus, um eine neue Datenbank zu erstellen.
CREATE DATABASE bank;
Erstelle nun mit der folgenden Abfrage eine neue Tabelle in der Datenbank.
CREATE TABLE bank.accounts (id INT PRIMARY KEY, balance DECIMAL);
Importiere anschließend Beispieldaten in die Tabelle.
INSERT INTO bank.accounts (1, 1000.50);
Überprüfe die Daten in der Datenbank mit der folgenden Abfrage.
SELECT * FROM bank.accounts;
Du erhältst die folgende Ausgabe.
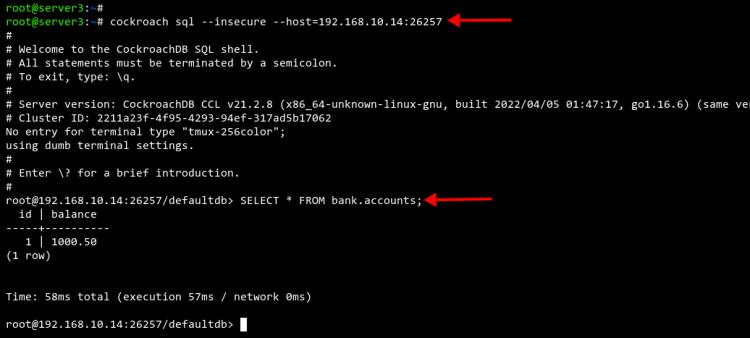
Wechsle als Nächstes zu Server2 oder Server3 und melde dich mit dem folgenden Befehl in der SQL-Shell cockroachdb an.
cockroach sql --insecure --host=192.168.10.14:26257
Nachdem du mit der SQL-Shell auf Server3 verbunden bist, führe die folgende Abfrage aus, um die Datenbankreplikation zu prüfen und zu verifizieren.
SELECT * FROM bank.accounts;
Du wirst sehen, dass die Datenbank und die Daten von Server11 automatisch auf Server2 und Server3 repliziert werden.
Fazit
Herzlichen Glückwunsch! Du hast jetzt den cockroachdb-Cluster auf Debian 11-Servern installiert und konfiguriert. Außerdem hast du gelernt, wie man sich mit der cockroachdb-Shell verbindet und grundlegende SQL-Befehle zum Erstellen einer Datenbank und zum Einfügen von Daten ausführt.