Wie man einen Kubernetes Cluster mit AWS CLI erstellt
Elastic Kubernetes Service (EKS) ist ein verwalteter Kubernetes-Service, der auf AWS gehostet wird.
Der Hauptgrund für die Nutzung von EKS ist die Entlastung von der Verwaltung von Pods, Nodes usw. Der Betrieb von Kubernetes in AWS erfordert derzeit ein hohes Maß an technischem Fachwissen und liegt oft außerhalb der Möglichkeiten vieler Unternehmen. Mit EKS wird die erforderliche Infrastruktur von Amazons „hauseigenem“ Team verwaltet, so dass die Nutzer/innen eine vollständig verwaltete Kubernetes-Engine erhalten, die entweder über eine API oder die Standard-Kubectl-Tools genutzt werden kann.
EKS unterstützt alle Kubernetes-Funktionen, einschließlich Namespaces, Sicherheitseinstellungen, Ressourcenkontingente und -toleranzen, Bereitstellungsstrategien, Autoscaler und mehr. EKS ermöglicht es dir, deine eigene Control Plane zu betreiben, lässt sich aber auch in AWS IAM integrieren, sodass du deine eigene Zugriffskontrolle auf die API aufrechterhalten kannst.
EKS wurde auf Amazons bestehender „Kubernetes-as-a-Service“-Lösung namens Elastic Container Service for Kubernetes (EKS) aufgebaut. EKS ist ein von AWS verwalteter Service, der die Bereitstellung, die Verwaltung und den Betrieb von Kubernetes-Clustern in der AWS Cloud vereinfacht.
Wenn du Kubernetes auf AWS betreibst, bist du für die Verwaltung der Control Plane (d.h. der Master- und Worker-Knoten) verantwortlich. Außerdem musst du dafür sorgen, dass der API-Server hochverfügbar und fehlertolerant ist usw.
EKS nimmt dir die Last der Verwaltung der Control Plane ab, sodass du dich auf den Betrieb deiner Kubernetes-Workloads konzentrieren kannst. Es wird am häufigsten für zustandslose Anwendungen wie Microservices verwendet, da die Control Plane von Amazon (EKS) verwaltet wird.
In diesem Leitfaden lernst du, wie du einen Kubernetes-Cluster auf AWS mit EKS erstellst. Du lernst, wie du einen administrativen Benutzer für deinen Kubernetes-Cluster anlegst. Du lernst auch, wie du eine App im Cluster bereitstellst. Schließlich wirst du deinen Cluster testen, um sicherzustellen, dass alles richtig funktioniert.
Los geht’s!
Voraussetzungen
- Ein AWS-Konto.
- Der Artikel setzt voraus, dass du mit Kubernetes und AWS vertraut bist. Wenn du das nicht bist, nimm dir bitte die Zeit, die Dokumentation zu beiden Systemen durchzulesen, bevor du mit dieser Anleitung beginnst.
Einen Admin-Benutzer mit Berechtigungen erstellen
Beginnen wir mit der Erstellung eines Admin-Benutzers für deinen Cluster.
1. Melde dich in deiner AWS-Konsole an und gehe zu IAM. Klicke auf Benutzer > Benutzer hinzufügen.


2. Auf dem nächsten Bildschirm gibst du einen Benutzernamen wie admin ein. WähleZugriffsschlüssel – Programmatischer Zugriff. Klicke auf Weiter: Berechtigungen

3Auf dem nächsten Bildschirm wählstdu Vorhandene Richtlinien direkt anhängen. Klicke auf AdministratorZugang. Klicke auf Weiter: Tags.
Die Richtlinie AdministratorAccess ist eine integrierte Richtlinie von Amazon Elastic Container Service (ECS). Sie bietet vollen Zugriff auf alle ECS-Ressourcen und alle Aktionen in der ECS-Konsole. Der Hauptvorteil dieser Richtlinie ist, dass wir keinen zusätzlichen Benutzer mit zusätzlichen Privilegien für den Zugriff auf den AWS EKS-Service erstellen oder verwalten müssen.
Dein Admin-Benutzer kann EC2-Instanzen, CloudFormation-Stacks, S3-Buckets usw. erstellen. Du solltest sehr vorsichtig sein, wem du diese Art von Zugriff gewährst.
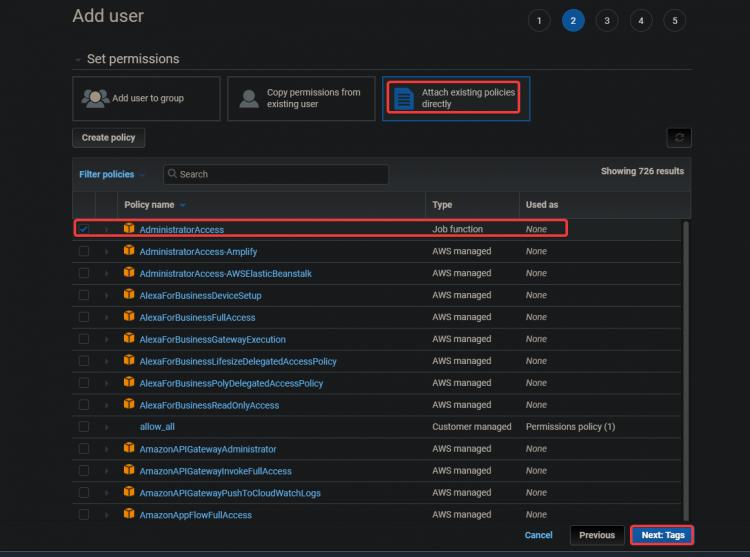
3.Auf dem nächsten Bildschirm klickst du auf Weiter: Überprüfung
4.Auf dem nächsten Bildschirm klickst du auf Benutzer erstellen.
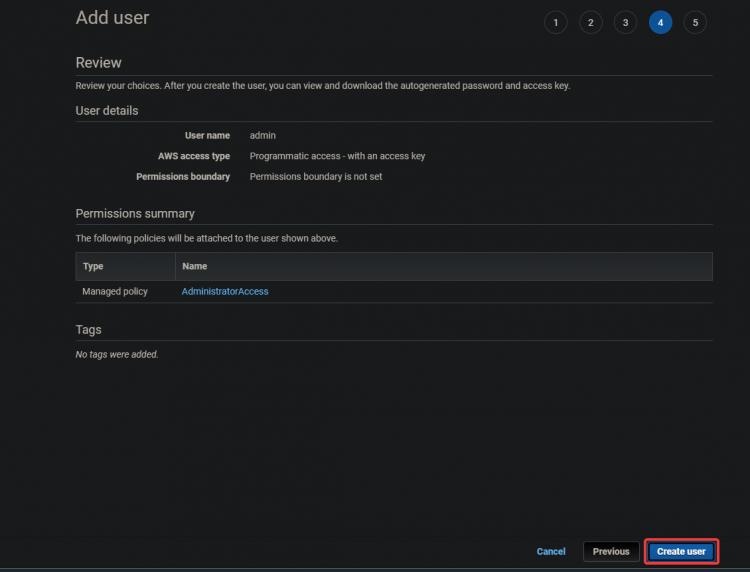
5. Auf dem nächsten Bildschirm erhältst du eine grüne Erfolgsmeldung. Auf diesem Bildschirm werden auch die Zugangsschlüssel-ID und der
Secret-Zugangsschlüssel angezeigt. Du wirst diese Schlüssel später für die Konfiguration deiner CLI-Tools benötigen, also notiere sie dir irgendwo.

Eine EC2-Instanz erstellen
Nachdem du den administrativen Benutzer angelegt hast, erstellen wir nun eine EC2-Instanz, die du als Kubernetes-Masterknoten verwenden kannst.
1. Gib EC2 in das Suchfeld ein. Klicke auf den EC2-Link. Klicke aufInstanz starten.

2. Wähle das Amazon Linux 2 AMI (HVM) für deine EC2-Instanz. Wir werden dieses Amazon Linux AMI verwenden, um später Kubernetes und andere benötigte Tools wie kubectl! und Docker zu installieren.
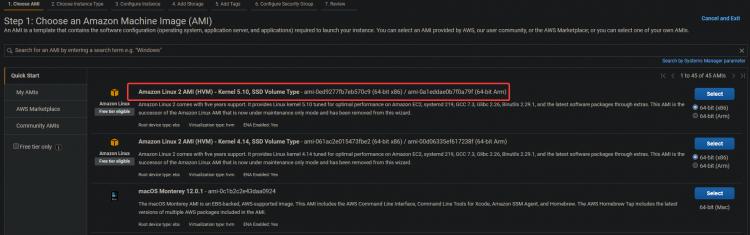
3. Auf dem nächsten Bildschirm klickst du auf Weiter: Details der Instanz konfigurieren.

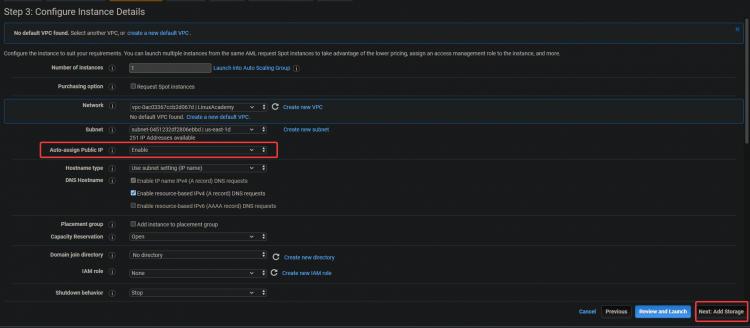
3.Aktiviereauf dem nächsten Bildschirmdie Option Öffentliche IP automatisch zuweisen. Da sich der Server in einem privaten Subnetz befindet, ist er von außen nicht erreichbar. Du kannst deinen Servern öffentliche IP-Adressen zuweisen, indem du eine Elastic IP-Adresse mit der Instanz verknüpfst. Auf diese Weise sind deine EC2 und ELK erreichbar. Klicke aufWeiter: Speicher.
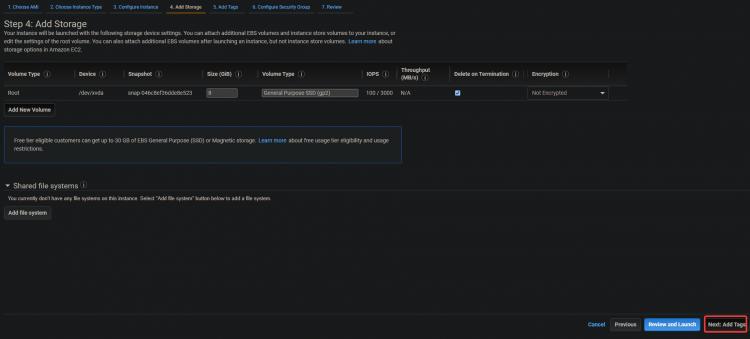
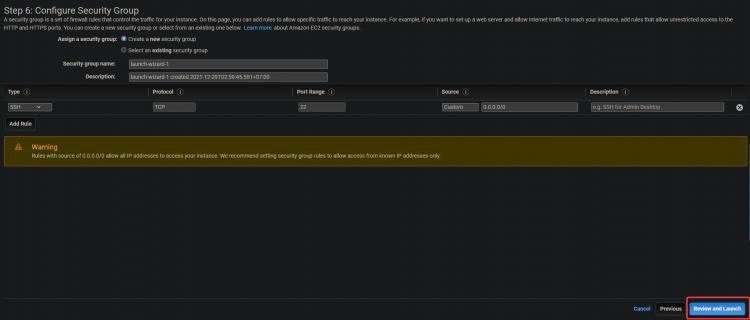
3. Auf dem nächsten Bildschirm klickst du auf Weiter: Tags hinzufügen > Weiter: Sicherheitsgruppe konfigurieren.
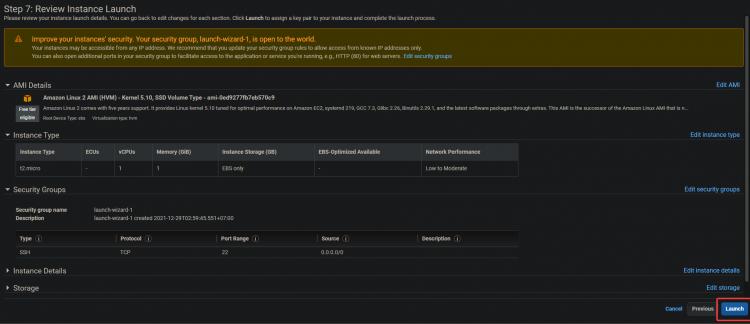
4. Auf dem nächsten Bildschirm klickst du aufÜberprüfen und Starten>Starten.
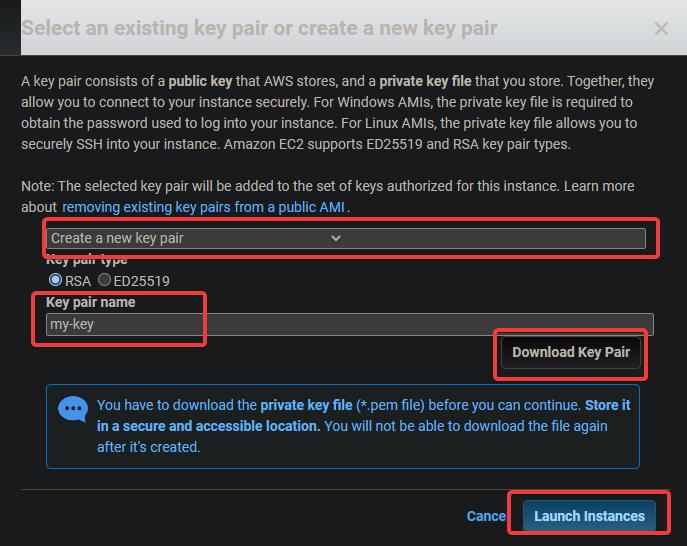
5. ein Schlüsselpaar-Dialog wird angezeigt. Klicke auf Ein neues Schlüsselpaar erstellen. Gib ihm einen Namen und lade die .pem-Datei herunter und speichere sie an einem sicheren Ort. Klicke auf Instanz starten.
Konfigurieren der Command Line Tools
Jetzt, wo du eine EC2-Instanz erstellt hast, musst du den Client dafür installieren. In der AWS-Sprache ist ein Client ein Befehlszeilen-Tool, mit dem du Cloud-Objekte verwalten kannst. In diesem Abschnitt erfährst du, wie du die Tools der Befehlszeilenschnittstelle (CLI) konfigurierst.
1. Navigiere zu deinem EC2 Dashboard. Du solltest sehen, dass deine neue EC2-Instanz läuft. Wenn das nicht der Fall ist, kann es sein, dass deine Instanz zum ersten Mal bootet. Warte 5 Minuten und versuche es erneut. Sobald deine Instanz läuft, klicke auf Verbinden.

2. Auf dem nächsten Bildschirm klickst du auf Verbinden.
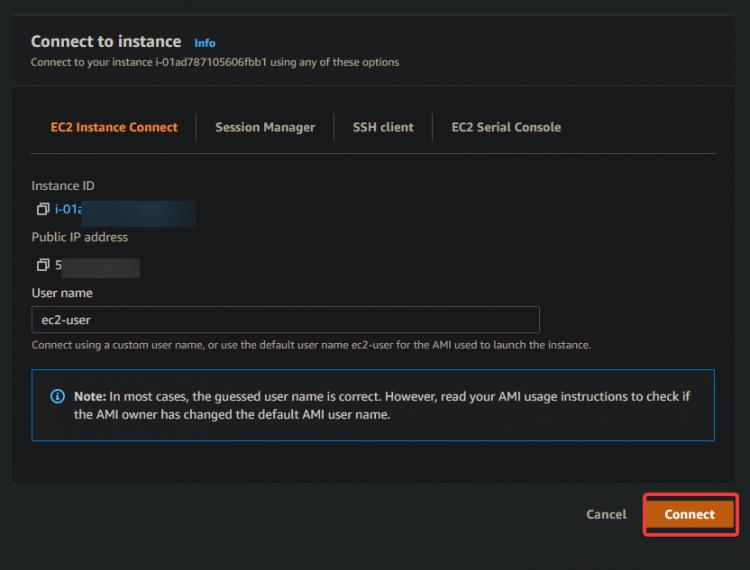
Du wirst zu einer interaktiven SSH-Sitzung in deinem Browser weitergeleitet. SSH ermöglicht es dir, dich sicher mit einem entfernten Server zu verbinden und dort zu arbeiten. Über die interaktive SSH-Sitzung können wir die Kommandozeilen-Tools für EKS und Kubernetes direkt auf deiner EC2-Instanz installieren.

Sobald du dich in die SSH-Sitzung eingeloggt hast, musst du als erstes deine aws-cli Version überprüfen. So stellst du sicher, dass du die neueste Version der AWS CLI verwendest. Die AWS CLI wird verwendet, um deinen Cluster zu konfigurieren, zu verwalten und mit ihm zu arbeiten.
Wenn deine Version veraltet ist, kann es zu Problemen und Fehlern bei der Erstellung des Clusters kommen. Wenn deine Version kleiner als 2.0 ist, musst du sie aktualisieren.
3. führeden folgenden Befehl aus, um deine CLI-Version zu überprüfen.
aws --version
Wie du in der untenstehenden Ausgabe sehen kannst, verwenden wir die Version 1.18.147 von aws-cli, die sehr veraltet ist. Aktualisiere das CLI auf die neueste verfügbare Version, die zum Zeitpunkt der Erstellung dieses Artikels v2+ ist.

4. führe den folgenden Befehl aus, um die neueste Version von AWS CLI auf deine EC2-Instanz herunterzuladen. curl lädt die Datei von der angegebenen URL herunter, -o gibt ihr einen Namen deiner Wahl und „awscli-exe-linux-x86_64.zip“ ist die Datei, die heruntergeladen werden soll
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"

5Sobald der Download abgeschlossen ist, führe den folgenden Befehl aus, um den Inhalt der heruntergeladenen Datei in das aktuelle Verzeichnis zu entpacken.
unzip awscliv2.zip
6. Als Nächstes führst du den Befehl which aws aus, um deinen Link auf die neueste Version von AWS CLI zu setzen. Dieser Befehl teilt dir mit, wo im PATH deiner Umgebung er zu finden ist, so dass du ihn von jedem Verzeichnis aus ausführen kannst.
which aws
Wie du in der folgenden Ausgabe sehen kannst, befindet sich die veraltete AWS CLI unter /usr/bin/aws.

7. Jetzt musst du deine aws-cli konfigurieren, indem du einen Update-Befehl mit einigen Parametern ausführst. Der erste Parameter./aws/install hilft uns, AWS CLI in das aktuelle Verzeichnis zu installieren. Der zweite Parameter –bin-dir gibt an, wo im PATH deiner Umgebung die AWS CLI zu finden ist, und der dritte Parameter –install-dir ist ein Pfad relativ zu bin-dir. Mit diesem Befehl stellst du sicher, dass alle deine Pfade auf dem neuesten Stand sind.
sudo ./aws/install --bin-dir /usr/bin --install-dir /usr/bin/aws-cli --update
8. Führe den Befehl aws –version erneut aus, um sicherzustellen, dass du die neueste Version verwendest.
aws --version
Du solltest die aktuell installierte AWS CLI-Version sehen. Wie du in der Ausgabe unten sehen kannst, verwenden wir jetzt v2.4.7 von AWS CLI. Das ist die neueste Version und wird dir bei der Konfiguration der nächsten Schritte keine Probleme bereiten.
![]()
9. Jetzt, da deine Umgebung richtig konfiguriert ist, musst du festlegen, mit welchem AWS-Konto du über die AWS CLI kommunizieren willst. Führe den folgenden Befehl aus, um die Umgebungsvariablen deines aktuell konfigurierten Kontos mit dem Alias aufzulisten, den du verwenden möchtest.
aws configure
Dadurch werden dir alle Umgebungsvariablen deines AWS-Kontos angezeigt, die derzeit konfiguriert sind. Die folgende Ausgabe sollte in etwa so aussehen. Damit das AWS CLI mit deinen Konten kommunizieren kann, musst du einige Konfigurationsparameter einrichten. Führe den folgenden Befehl aus, der dich durch einen Konfigurationsassistenten führt, um dein AWS-Konto einzurichten.
- AWS-Zugangsschlüssel-ID [Keine]: Gib den AWS-Zugangsschlüssel ein, den du zuvor notiert hast.
- AWS Secret Access Key [None]: Gib den geheimen AW S-Zugangsschlüssel ein, den du zuvor notiert hast.
- Du musst auch den Namen der Standardregion angeben, in der sich dein EKS-Cluster befinden wird. Du solltest eine AWS-Region auswählen, in der sich dein gewünschter EKS-Cluster befinden wird und die dir am nächsten liegt. In diesem Lehrgang haben wir uns für us-east-1 entschieden, weil sie geografisch in unserer Nähe liegt und für die nächsten Schritte im Lehrgang einfach zu verwenden ist.
- Standard-Ausgabeformat [Keine]: Gib json als Standard-Ausgabeformat an, da es für uns sehr nützlich ist, um die Konfigurationsdateien später einzusehen.

Nachdem du nun deine AWS CLI-Tools eingerichtet hast. Jetzt ist es an der Zeit, das Kubernetes CLI-Tool namens kubectl in deiner Umgebung zu konfigurieren, damit du mit deinem EKS-Cluster interagieren kannst.
Kubectl ist die Befehlszeilenschnittstelle für Kubernetes. Mit Kubectl kannst du Anwendungen verwalten, die auf Kubernetes-Clustern laufen. Kubectl ist auf Linux- und MacOS-Systemen nicht standardmäßig installiert. Du kannst Kubectl auf anderen Systemen installieren, indem du den Anweisungen auf der Kubernetes-Website folgst.
10. Führe den unten stehenden Befehl aus, um die kubectl-Binärdatei herunterzuladen. Eine Binärdatei ist eine Computerdatei mit der Endung „.bin“, die nur auf bestimmten Computertypen ausführbar ist. So können verschiedene Computertypen auf einfache Weise Dateien gemeinsam nutzen. Wir verwenden kubectl binary, weil kubectl binary plattformunabhängig ist. Es funktioniert auf jedem System, auf dem ein Unix-ähnliches Betriebssystem läuft, einschließlich Linux und Mac OS.
curl -o kubectl https://amazon-eks.s3.us-west-2.amazonaws.com/1.16.8/2020-04-16/bin/linux/amd64/kubectl
11. Führe den Befehl chmod aus, um die kubectl binary ausführbar zu machen. Der chmod-Befehl ist ein Unix- und Linux-Befehl, mit dem du die Zugriffsrechte für Dateien und Verzeichnisse ändern kannst. Der Linux-Befehl chmod verwendet das oktale Zahlensystem, um die Zugriffsrechte für jeden Benutzer festzulegen. Kubectl kann jetzt auf deinem lokalen Rechner verwendet werden.
chmod +x ./kubectl
12. Führe den folgenden Befehl aus, um ein kubectl-Verzeichnis in deinem Ordner $HOME/bin zu erstellen und das kubectl-Binary dorthin zu kopieren. Der Befehl mkdir -p $HOME/bin erstellt ein Unterverzeichnis bin in deinem Home-Verzeichnis. Der Befehl mkdir wird verwendet, um neue Verzeichnisse oder Ordner zu erstellen. Mit der Option -p wird der Befehl mkdir angewiesen, automatisch alle notwendigen übergeordneten Verzeichnisse für das neue Verzeichnis zu erstellen. $HOME/bin ist eine Umgebungsvariable, die den Pfad zu deinem Heimatverzeichnis speichert. Jeder Linux-Benutzer hat das Verzeichnis $HOME/bin in seinem Dateisystem. Das &&-Konstrukt wird als logischer UND-Operator bezeichnet. Es wird verwendet, um Befehle zu gruppieren, so dass mehr als ein Befehl gleichzeitig ausgeführt werden kann. Das &&-Konstrukt ist nicht notwendig, damit dieser Befehl funktioniert, aber es ist eine bewährte Methode.
Der Befehl cp ./kubectl $HOME/bin/kubectl kopiert die lokale kubectl-Binärdatei in dein kubectl-Verzeichnis und benennt die Datei in kubectl um. Der Befehl export tut, was er sagt: Er exportiert eine Umgebungsvariable in den Speicher der Shell, so dass sie von jedem Programm, das von dieser Shell aus gestartet wird, verwendet werden kann. In unserem Fall müssen wir kubectl mitteilen, wo sich unser kubectl-Verzeichnis befindet, damit es die kubectl-Binärdatei finden kann.
mkdir -p $HOME/bin && cp ./kubectl $HOME/bin/kubectl && export PATH=$PATH:$HOME/bin
13. Führe den folgenden Befehl kubectl version aus, um zu überprüfen, ob kubectl richtig installiert ist. Der Befehl kubectl version –short –client gibt eine gekürzte Version der kubectl-Version in einer gut formatierten, für Menschen lesbaren Kubernetes-REST-API-Antwort aus. Mit der Option –client kann kubectl die formatierte Version der REST-API-Antwort von Kubernetes ausgeben, die über alle Versionen hinweg konsistent ist.
Die Option –short weist kubectl an, grundlegende Informationen in einer kompakten Form mit einer Nachkommastelle für Fließkommazahlen und einem abgekürzten Zeitformat, das dem –format entspricht, auszugeben. Du solltest eine Ausgabe wie die folgende sehen. Diese Ausgabe zeigt uns, dass wir kubectl erfolgreich installiert haben und die richtige Version verwenden.

Als Letztes musst du in diesem Abschnitt das Tool eksctl cli für die Verwendung deines Amazon EKS-Clusters konfigurieren. Das Tool eksctl cli ist eine Befehlszeilenschnittstelle, mit der du Amazon EKS-Cluster verwalten kannst. Es kann Cluster-Anmeldeinformationen erstellen, die Cluster-Spezifikationen aktualisieren, Worker Nodes erstellen oder löschen und viele andere Aufgaben ausführen.
14. Führe die folgenden Befehle aus, um das eksctl cli Tool zu installieren und seine Version zu überprüfen.
curl --silent --location "https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$(uname -s)_amd64.tar.gz" | tar xz -C /tmp && sudo mv /tmp/eksctl /usr/bin
eksctl version

Einrichten eines EKS-Clusters
Jetzt, wo du deine EC2 und die AWS CLI-Tools hast, kannst du deinen ersten EKS-Cluster bereitstellen.
1. Führe den Befehl eksctl create cluster aus, um einen Cluster namens dev in der Region us-east-1 mit einem Master- und drei Core-Knoten bereitzustellen.
eksctl create cluster --name dev --version 1.21 --region us-east-1 --nodegroup-name standard-workers --node-type t3.micro --nodes 3 --nodes-min 1 --nodes-max 4 --managed
Der Befehl eksctl create cluster erstellt einen EKS-Cluster in der Region us-east-1 unter Verwendung der von Amazon für diese spezielle Konfiguration empfohlenen Standardeinstellungen und übergibt alle Argumente in Anführungszeichen ( “ ) oder als Variablen ( ${ } ) entsprechend.
Der Parameter name wird verwendet, um den Namen des EKS-Clusters zu definieren. version ist die Version, die der Cluster verwenden soll. In diesem Beispiel bleiben wir bei Kubernetes v1.21.2, aber du kannst auch andere Optionen ausprobieren.
nodegroup-name ist der Name der Knotengruppe, die der Cluster für die Verwaltung der Arbeitsknoten verwenden soll. In diesem Beispiel hältst du es einfach und verwendest nur Standard-Worker, was bedeutet, dass deine Worker-Knoten standardmäßig über eine vCPU und 3 GB Speicher verfügen.
nodes ist die Gesamtzahl der Core Worker Nodes, die du in deinem Cluster haben möchtest. In diesem Beispiel werden drei Nodes angefordert. nodes-min und nodes-max legen die minimale und maximale Anzahl der Nodes fest, die in deinem Cluster erlaubt sind. In diesem Beispiel werden mindestens ein, aber nicht mehr als vier Worker Nodes erstellt.
2. Du kannst zu deiner CloudFormation-Konsole navigieren, um den Fortschritt der Bereitstellung zu überwachen.
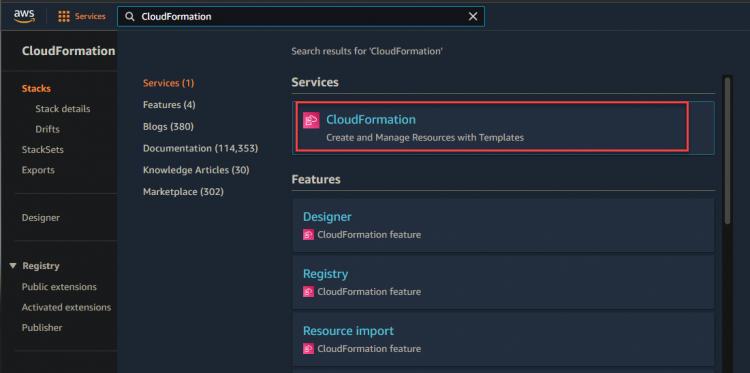
Wie unten zu sehen ist, wird dein Dev Stack gerade erstellt.
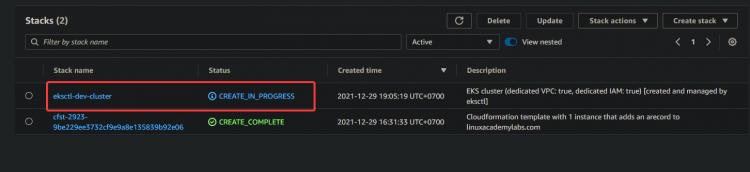
3. Klicke auf den Hyperlink Dev Stack > Ereignis. Du siehst eine Liste von Ereignissen im Zusammenhang mit dem Erstellungsprozess. Warte ab, bis der Bereitstellungsprozess abgeschlossen ist – das kann je nach deinen Umständen bis zu 15 Minuten dauern – und überprüfe den Status des Stacks in der CloudFormation-Konsole.
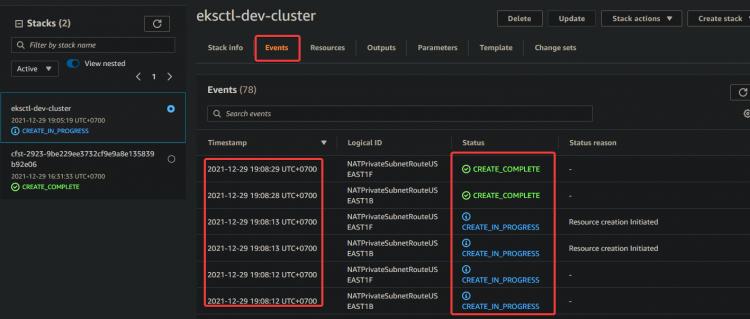
4. Nachdem du gewartet hast, bis die Bereitstellung des Stacks abgeschlossen ist, navigierst du zu deiner CloudFormation-Konsole und siehst den Status deines Dev-Stacks: CREATE_COMPLETE.

Navigiere nun zu deiner EC2 Konsole. Im EC2 Dashboard siehst du einen Master Node und drei Core Nodes. Diese Ausgabe bestätigt, dass du den EKS-Cluster erfolgreich eingerichtet hast.

5. Führe den folgenden eksctl-Befehl aus, um die Details des Dev-Clusters zu erfahren, z. B. die Cluster-ID und die Region.
eksctl get cluster

6. Führe den Befehl aws eks update aus, um die Anmeldedaten für den Remote Worker Node zu erhalten. Dieser Befehl muss auf jedem Computer ausgeführt werden, den du mit dem Cluster verbinden willst. Er lädt die Anmeldeinformationen für dein kubectl herunter, damit du aus der Ferne auf den EKS Kubernetes Cluster zugreifen kannst, ohne AWS Access Zugangsschlüssel zu verwenden.
aws eks update-kubeconfig --name dev --region us-east-1
![]()
Bereitstellen deiner Anwendung auf dem EKS Cluster
Jetzt, wo du deinen EKS Cluster eingerichtet hast. Lass uns deine erste Anwendung auf deinem EKS Cluster bereitstellen. In diesem Abschnitt lernst du, wie du einen nginx Webserver zusammen mit einem Load Balancer als Beispielanwendung bereitstellst.
1. Führe den folgenden Befehl aus, um git auf deinem System zu installieren. Du brauchst git, um den Code des nginx-Webservers von GitHub zu klonen.
sudo yum install -y git
2. Führe den Befehl git clone aus, um den Code des nginx-Webservers von GitHub in dein aktuelles Verzeichnis zu klonen.
git clone https://github.com/ata-aws-iam/htf-elk.git
3. Führe den Befehl cd htf-elk aus, um das Arbeitsverzeichnis in das Verzeichnis der nginx-Konfigurationsdateien zu ändern.
cd htf-elk
4. Führe den Befehl ls aus, um die Dateien im aktuellen Verzeichnis aufzulisten.
ls
Du wirst sehen, dass die folgenden Dateien in deinem nginx-Verzeichnis vorhanden sind.
![]()
5. Führe den Befehl cat aus, um die Datei nginx-deployment.yaml zu öffnen und du wirst den folgenden Inhalt in dieser Datei sehen.
cat nginx-deployment.yaml

- apiVersion: apps/v1 ist die Kern-Kubernetes-API
- kind: Deployment ist die Art der Ressource, die für diese Datei erstellt wird. Bei einem Deployment wird ein Pod pro Container erstellt.
- metadata: gibt die Metadatenwerte an, die bei der Erstellung eines Objekts verwendet werden sollen
- name: nginx-deployment ist der Name oder die Bezeichnung für diese Bereitstellung. Wenn es keinen Wert hat, wird der Einsatzname aus dem Verzeichnisnamen übernommen.
- labels: stellt Labels für die Anwendung bereit. In diesem Fall wird es für das Service-Routing über Elastic Load Balancing (ELB) verwendet
- env: dev beschreibt eine Umgebungsvariable, die durch einen String-Wert definiert ist. Auf diese Weise kannst du deinem Container dynamische Konfigurationsdaten zur Verfügung stellen.
- spec: Hier legst du fest, wie viele Replikate du erstellen willst. Du kannst die Eigenschaften angeben, auf denen die einzelnen Replikate basieren sollen.
- Replikate: 3 erstellt drei Replikate dieses Pods in deinem Cluster. Diese werden auf die verfügbaren Worker Nodes verteilt, die dem Label Selector entsprechen.
- containerPort: 80 ordnet einen Port des Containers einem Port auf dem Host zu. In diesem Fall wird Port 80 des Containers auf Port 30000 deines lokalen Rechners abgebildet.
6.führe den Befehl cat aus, um die Servicedatei nginx-svc.yaml zu öffnen. Du wirst den folgenden Inhalt in dieser Datei sehen.
cat nginx-svc.yaml
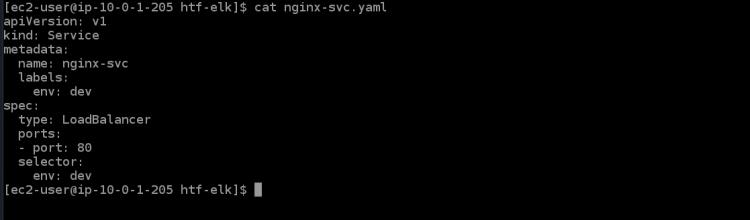
7. Führe den Befehl kubectl apply aus, um den nginx-Dienst in deinem Kubernetes-Cluster zu erstellen. Es wird ein paar Minuten dauern, bis der EKS-Cluster die ELB für diesen Dienst bereitstellt.
kubectl apply -f ./nginx-svc.yaml
![]()
8. Führe den Befehl kubectl get service aus, um Informationen über den nginx-Dienst zu erhalten, den du gerade erstellt hast.
kubectl get service
Du wirst die folgende Ausgabe erhalten. ClusterIP ist die interne Kubernetes-IP, die diesem Dienst zugewiesen wurde. Der LoadBalancer ELB-Name ist ein eindeutiger Bezeichner für diesen Dienst. Es wird automatisch ein ELB auf AWS erstellt und ein öffentlicher Endpunkt für diesen Dienst bereitgestellt, der von Diensten deiner Wahl wie z.B. Webbrowser (Domain Name) oder API-Clients erreicht werden kann. Er ist über eine IP-Adresse deiner Wahl erreichbar.
Der Load Balancer ELB mit dem Namen a6f8c3cf0fe3a468d8828db6059ef05e-953361268.us-east-1.elb.amazonaws.com hat den Port 32406, der auf den Container-Port 80 abgebildet werden soll. Notiere dir den DNS-Hostnamen des Load Balancers ELB aus der Ausgabe; du brauchst ihn später für den Zugriff auf den Dienst.
![]()
9. Führe den Befehl kubectl apply aus, um die Bereitstellung für deinen Cluster zu übernehmen.
kubectl apply -f ./nginx-deployment.yaml
![]()
10. Führe den Befehl kubectl get deployment aus, um die Details über die soeben erstellte nginx-Bereitstellung zu erhalten.
kubectl get deployment
![]()
11. Führe den folgenden Befehl aus, um deine nginx-Anwendung über den Load Balancer aufzurufen. Du wirst die Willkommensseite von nginx in deinem Terminal/Konsole sehen, die bestätigt, dass deine nginx-Anwendung wie erwartet funktioniert. Ersetze <LOAD_BALANCER_DNS_HOSTNAME> durch den DNS-Hostnamen des Load Balancers, den du oben notiert hast.
curl "<LOAD_BALANCER_DNS_HOSTNAME>"

12. Du kannst auch über den Browser auf deine nginx-Anwendung zugreifen, indem du den DNS-Hostnamen des Load Balancers kopierst und in den Browser einfügst.

Überprüfe die Hochverfügbarkeitsfunktion (HA) für deinen Cluster
Nachdem du deinen Cluster erfolgreich erstellt hast, kannst du die HA-Funktion testen, um sicherzustellen, dass sie wie erwartet funktioniert.
Kubernetes unterstützt Multi-Nodes Deployments mit Hilfe von speziellen Controllern, die zusammenarbeiten, um replizierte Pods oder Dienste zu erstellen und zu verwalten. Zu diesen Controllern gehören Deployments, ReplicationController, Job und DaemonSet.
Ein DeploymentController wird verwendet, um die Replikation auf Pod- oder Service-Ebene zu steuern. Wenn dein Pod keine Ressourcen mehr hat, löscht er alle Pods dieses Replikationscontrollers (mit Ausnahme desjenigen, der auf dem Masterknoten läuft) und erstellt neue Replikate dieses Pods. Auf diese Weise erreichst du eine sehr hohe Betriebszeit für deine Anwendungen.
1. rufedein EC2 Dashboard auf und stoppe alle drei Worker Nodes.

2. Führe den folgenden Befehl aus, um den Status deiner Pods zu überprüfen. Du wirst verschiedene Status erhalten: Terminating, Running und Pending für alle deine Pods. Denn sobald du alle Worker Nodes gestoppt hast, versucht EKS, alle Worker Nodes und Pods neu zu starten. Du kannst auch einige neue Nodes sehen, die du an ihrem Alter(50 Jahre) erkennen kannst.
kubectl get pod

Es dauert einige Zeit, bis die neue EC2-Instanz und die Pods hochgefahren sind. Sobald alle Worker Nodes hochgefahren sind, siehst du, dass alle neuen EC2-Instanzen wieder den Status “ Running“ haben.
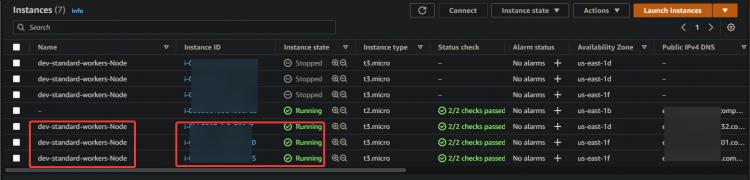
3. Führe denkubectl get Serviceerneut aus. Du kannst sehen, dass ESK einen neuen nginx-Dienst und einen neuen DNS-Namen für deinen Load Balancer erstellt.
kubectl get service

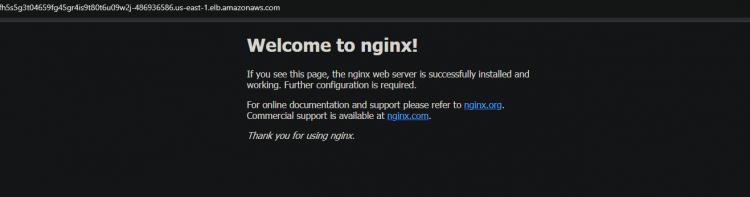
Kopiere den neuenDNSund füge ihnin deinen Browserein. Du bekommst wieder die Begrüßung von der Nginx-Seite. Diese Ausgabe bestätigt, dass dein HA wie vorgesehen funktioniert.
Fazit
In diesem Artikel hast du gelernt, wie du deinen EKS-Cluster einrichtest. Du hast auch überprüft, ob die Hochverfügbarkeitsfunktion funktioniert, indem du alle deine Worker Nodes gestoppt und den Status deiner Pods überprüft hast. Du solltest jetzt in der Lage sein, EKS-Cluster mit kubectl zu erstellen und zu verwalten.