Wie man eine große Archivdatei mit dem Befehl Split unter Linux in mehrere kleine Dateien aufteilt
Obwohl einer der Hauptgründe für die Erstellung von Archiven die einfache Handhabung und Übertragung ist, ist die komprimierte Datei selbst manchmal so groß, dass es zu einem Albtraum wird, sie über das Netzwerk zu übertragen, besonders wenn die Netzwerkgeschwindigkeit langsam ist.
Also, was sollte in solchen Fällen getan werden? Gibt es eine Lösung für dieses Problem? Nun, ja – eine Lösung ist die Aufteilung der komprimierten Datei in kleinere Bits, die leicht über das Netzwerk übertragen werden können. Am Zielort können Sie sie wieder zusammenfügen, um das Originalarchiv zu erhalten.
Wenn die Lösung interessant klingt und Sie genau verstehen wollen, wie dies unter Linux möglich ist, werden Sie sich freuen, dass wir in diesem Tutorial Schritt für Schritt alle wichtigen Details besprechen werden.
Wie man große Archive aufteilt
Es gibt ein Befehlszeilenprogramm – Split genannt – das Ihnen hilft, Dateien in Stücke zu teilen. Es wird auf den meisten Linux-Distributionen sofort installiert, so dass Sie keine zusätzlichen Schritte zum Herunterladen und Installieren durchführen müssen. Die Syntax dieses Befehls lautet wie folgt:
split [OPTION]... [INPUT [PREFIX]]
Hier steht INPUT für den Namen der Datei, die in kleinere Bits aufgeteilt werden soll, und PREFIX ist der Text, dem der Name der Ausgabedateien vorangestellt werden soll. OPTION ist in unserem Fall -b, so dass wir die Größe der Ausgabedateien festlegen können.
Um die Verwendung von Split anhand eines Beispiels zu verstehen, benötigen Sie zunächst eine komprimierte Datei, die Sie aufteilen möchten. Zum Beispiel hatte ich die folgende 60MB.zip-Datei in meinem Fall:

Hier ist der Befehl Split in Aktion:
![]()
Wie Sie sehen können, habe ich mit der Option -b den Befehl Split aufgerufen, die große.zip-Datei in gleiche Teile von je 20 MB zu zerlegen und dabei den vollständigen Namen der komprimierten Datei sowie den Präfixtext anzugeben.
So habe ich überprüft, ob der Befehl Split tatsächlich das getan hat, worum er gebeten wurde:

Wie aus der Ausgabe im obigen Screenshot ersichtlich ist, wurden drei Dateien mit Namen, einschließlich des von mir gelieferten Präfixes und einem Gewicht von je 20 MB, in der Ausgabe erzeugt.
Natürlich können Sie neben.zip-Dateien auch andere Arten von komprimierten Dateien mit der oben genannten Methode aufteilen. Hier ist zum Beispiel, wie ich den gleichen Befehl verwendet habe, den wir zuvor besprochen haben, um eine.tar.xz-Datei aufzuteilen:
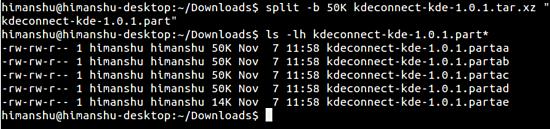
Wie Sie inzwischen verstanden haben, müssen Sie, wenn Sie eine Datei in mehrere Chunks aufteilen wollen, die in MBs groß sein sollen, den Buchstaben M mit der numerischen Zahl verwenden, die Sie auf der Befehlszeile angeben. Und wenn – wie der gerade besprochene Fall – die Dateien in KBs groß sein sollen, sollten Sie den Buchstaben K verwenden.
Bisher haben wir nur die Option -b verwendet, die der Befehl Split bietet; das liegt daran, dass er das tut, was wir wollen – dem Befehl sagen, die Eingabedatei entsprechend der Größe, die dieser Option auf der Befehlszeile folgt, aufzuteilen. Abhängig von Ihrem Fall und Ihrer Anforderung können Sie jedoch einige der anderen Optionen verwenden, die der Befehl Split bietet.
Im Folgenden finden Sie die Liste der Optionen zusammen mit einer kurzen Erklärung, was sie tun:
- -a, –suffix-length=N : erzeugt Suffixe der Länge N (Standard 2)
- —add additional-suffix=SUFFIX : fügt einen zusätzlichen SUFFIX an Dateinamen an.
- -b, –bytes=SIZE : SIZE Bytes pro Ausgabedatei setzen
- -C, –line-bytes=SIZE : setzt höchstens SIZE Bytes von Zeilen pro Ausgabedatei ein.
- -d, –numerische Suffixe[=FROM]: Verwenden Sie numerische Suffixe anstelle von alphabetisch. FROM ändert den Startwert (Standard 0).
- -e, –elide-empty-files : erzeugt keine leeren Ausgabedateien mit ‚-n‘.
- –filter=COMMAND : schreibt in die Shell COMMAND; Dateiname ist $FILE
- -l, –lines=NUMBER : Anzahl der Zeilen pro Ausgabedatei setzen
- -n, –n, –number=CHUNKS : erzeugt CHUNKS-Ausgabedateien.
- –u, –ungepuffert: Kopiert sofort die Eingabe in die Ausgabe mit‘-n r/….‘.
Bisher haben wir nur darüber diskutiert, wie man ein großes Archiv in mehrere kleinere Teile aufteilen kann. Unnötig zu sagen, dass das keinen Sinn macht, bis man auch weiß, wie man sie wieder zusammenfügt, um die ursprüngliche komprimierte Datei zu erhalten. Also, so können Sie das machen:
Es gibt kein spezielles Befehlszeilenprogramm, um die kleineren Chunks zu verbinden, da der gute alte Cat-Befehl in der Lage ist, diese Aufgabe zu erledigen. Hier ist zum Beispiel, wie ich die Datei Kaku-linux32.zip über den Befehl Cat abgerufen habe:
![]()
Sie können das abgerufene Archiv extrahieren und mit dem Original vergleichen, um sicherzustellen, dass sich nichts geändert hat.
Fazit
Wenn Sie ein Linux-Benutzer sind und Ihre tägliche Arbeit darin besteht, mit großen komprimierten Dateien zu spielen und sie mit anderen über das Netzwerk zu teilen, gibt es gute Chancen, dass Sie in einigen Fällen ein Archiv aufteilen möchten. Natürlich ist die in diesem Tutorial erwähnte Lösung vielleicht nicht die einzige, die verfügbar ist, aber es ist sicherlich eine der einfachsten und aufwendigsten.
Wenn Sie einen anderen Ansatz verwenden, um große Archive aufzuteilen und sie dann wieder zusammenzufügen, und Ihre Lösung mit anderen teilen möchten, können Sie dies in den Kommentaren unten tun.